A CLI based eclectic set of geochemical data manipulation, QC and plotting tools.
Pygeochemtools is a python library and command line interface tool to enable rapid manipulation, filtering, QC and plotting
of geochemical data. It is primarily designed to allow people with limited or no coding experience to deal with
very large datasets when programs like Excel will struggle. It is designed to natively load and manipulate the geochemical datasets output by the Geological Survey of South Australia, but will easily handle other datasets with a little bit of configuration in later updates.
For more information checkout the pygeochemtools documentation.
Project Features
Currently pygeochemtools provides the following functionality:
Filter large datasets based on a list of elements, sample type or drillhole numbers (or a combination of all three) and convert from long to wide format.
Add detailed geochemical methods columns onto the SARIG geochemical dataset.
Extract single element datasets from large geochemical datasets.
Plot maximum down hole geochemical data maps.
Plot maximum down hole chemistry per interval geochemical data maps.
Getting Started
The project’s documentation contains a section to help you get started as a user or
developer of the library.
Development Prerequisites
If you’re going to be working in the code (rather than just using the library), you’ll want a few utilities.
See also the list of contributors who participated in this project.
LicenseMIT License
Copyright (c) Rian Dutch
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the “Software”), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
FalsoJNI (falso as in fake from Italian) is a simple, zero-dependency fake
JVM/JNI interface written in C.
It is created mainly to make JNI-heavy Android→PSVita ports easier, but probably
could be used for other purposes as well.
Setup
Since there are no dependencies, FalsoJNI is not supplied with a Makefile of its
own, so to get started just include in your own Makefile/CMakeLists.txt
all the source files:
Second thing you need to do, is to create your own FalsoJNI_Impl file. You
will use it later to provide implementations for custom JNI Methods (the
ones called with jni->CallVoidMethodV and similars) and Fields.
To do this, from FalsoJNI_ImplSample.h copy the definitions between
COPY STARTING FROM HERE! and COPY UP TO HERE! to your project in any .c
file (you could also split it up into several files if you need to).
After that, you already init FalsoJNI and supply JNIEnv and JavaVM objects
to your client application, like this:
That’s it for the basic setup. In a theoretical situation where your client
application doesn’t use any Methods or Fields, you’re done here.
Otherwise, read on.
Implementing Methods
Step 1. Create functions
The easiest way to figure out which methods you need to implement is to
run the app as-is and look for FalsoJNI’s errors in logs, particularly with
GetMethodID / GetStaticMethodID functions:
[ERROR][/tmp/soloader/FalsoJNI.c:295][GetMethodID] [JNI] GetMethodID(env, 0x83561570, "SetShiftEnabled", "(Z)V"): not found
[ERROR][/tmp/soloader/FalsoJNI.c:295][GetMethodID] [JNI] GetMethodID(env, 0x83561570, "Shutdown", "()V"): not found
Two important things you get from this log are the method name
("SetShiftEnabled") and the method signature ("(Z)V").
You can learn what each symbol in Java type signature means here.
To cut on the long details, here are a few self-explanatory examples of how
Java method signatures are translated into FalsoJNI-compatible implementations:
// FalsoJNI always passes arguments as a va_list to be able to make single// function implementation no matter how it is called (i.e. CallMethod,// CallMethodV, or CallMethodA ).// "SetShiftEnabled", "(Z)V"voidSetShiftEnabled(jmethodIDid, va_listargs) { // V (ret type) is a voidjbooleanarg=va_arg(args, jboolean); // Z is a boolean// do something
}
// "GetDisplayOrientationLock", "()I"jintGetDisplayOrientationLock(jmethodIDid, va_listargs) { // I (ret type) is an integer// no arguments herereturn0;
}
// "GetUsername", "(Ljava/lang/String;)Ljava/lang/String;"jstringGetUsername(jmethodIDid, va_listargs) { // Ljava/lang/String; (ret type) is a jstringjstring_email=va_arg(args, jstring);
// If you want to work with Java strings, always use respective JNI methods!// They are NOT c-strings.constchar*email=jni->GetStringUTFChars(&jni, _email, NULL);
constchar*username=MyCoolFunctionToLookupUsername(_email);
jni->ReleaseStringUTFChars(&jni, _email, email);
returnjni->NewStringUTF(&jni, username);
}
// "read", "([BII)I"jintInputStream_read(jmethodIDid, va_listargs) { // I (ret type) is an integerjbyteArray_b=va_arg(args, char*); // [B is a byte array.jintoff=va_arg(args, int); // I is an intjintlen=va_arg(args, int); // I is an int// Before accessing/changing the array elements, we have to do the following:JavaDynArray*jda= (JavaDynArray*) _b;
if (!jda) {
log_error("[java.io.InputStream.read()] Provided buffer is not a valid JDA.");
return0;
}
char*b=jda->array; // Now this array we can work with
}
Pay great attention to the last example. Java arrays are notably different
from C arrays by always having the array size information with them, so
FalsoJNI mimics Java arrays behavior with a special struct, JavaDynArray
(or jda in short).
Every time you receive an array of any kind as an argument, you have to get
the “real”, underlying array from it like shown in the example. You can also
use jda_sizeof(JavaDynArr *) function to get the length of the array you
are operating on.
If you need to return an array in Java method implementation, — likewise.
Work with jda->array, return jda.
Also notice the second-to-last example to see how you can work with Java strings.
Step 2. Put them in relevant arrays
Now that you have your implementations in place, the only thing left to do
to allow the client application to use them is to fill in the arrays in the
implementation file you copied from FalsoJNI_ImplSample.h earlier.
You just need to figure out the return types for your methods and come up with
any (unique!) method IDs you like. Example of filling the arrays for methods
from Step 1:
With Fields, it’s basically the same thing. Run your app, look for the errors
in GetFieldID, GetStaticFieldID to figure out the needed Fields names and
signatures (well, just types in this case).
When you know them, fill in the arrays in the same fashion:
Everything else will be taken care of by FalsoJNI.
Tips
There is a very verbose logging in this lib to debug difficult situations.
Either define FALSOJNI_DEBUGLEVEL or edit FalsoJNI.h if you need to change
the verbosity level:
There are things in JNI that can not be implemented without some terrible
overengineering. If you come across one of them, the library will throw
a warning-level log at you.
I tried to keep the code as clean and self-explanatory as possible, but
didn’t have time yet to write a proper documentation. As a direction for
further info, look at FalsoJNI_ImplBridge.h header for common type definitions
and JDA functions.
Keep track of references and destroy objects when there aren’t any left.
Dry Run mode that would record methods/fields definitions to
FalsoJNI_Impl.c for you.
Credits
TheFloW and Rinnegatamante for fake JNI interfaces implementations
in gtasa_vita that
served as inspiration and basis for this lib.
License
This software may be modified and distributed under the terms of
the MIT license. See the LICENSE file for details.
Contains parts of Dalvik implementation of JNI interfaces,
copyright (C) 2008 The Android Open Source Project,
licensed under the Apache License, Version 2.0.
Includes converter.c and converter.h,
copyright (C) 2015 Jonathan Bennett jon@autoitscript.com,
licensed under the Apache License, Version 2.0.
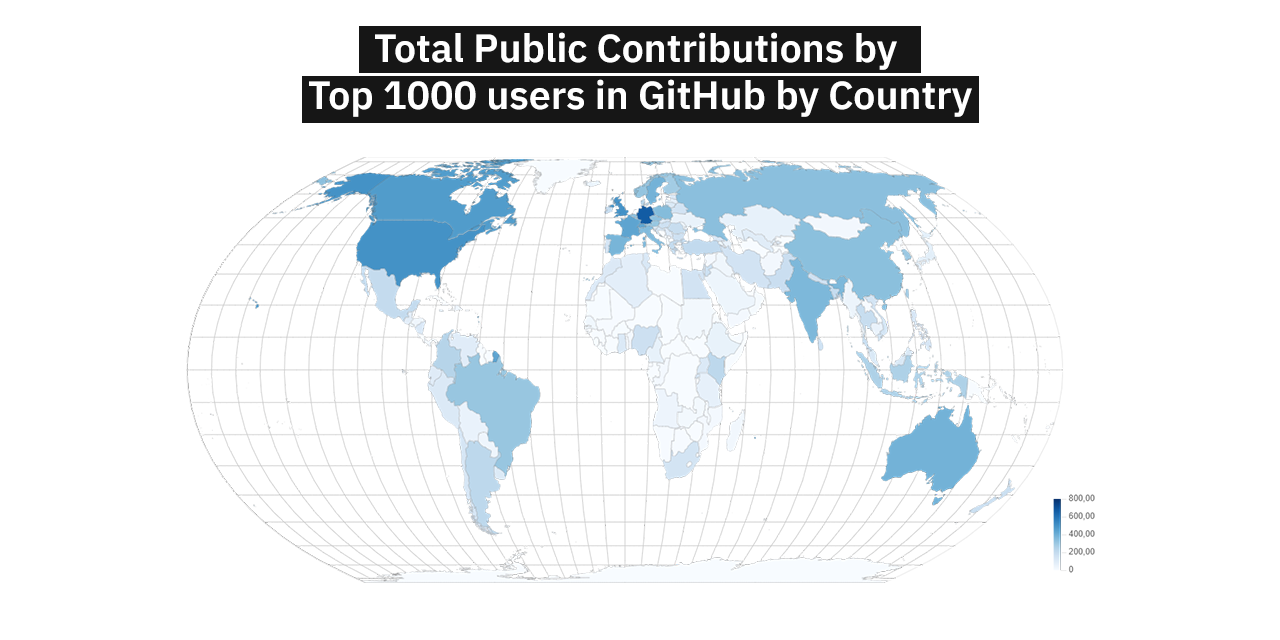
List of most active GitHub users based on public contributionsprivate contributions and number of followers by country or state. The list updated 2025/8/29 3:05 PM UTC.
This repository contains users 19 countries and 130 cities.
To get into the list you need to have minimum number of followers that varies in each country. The list can be found in config.json.
List of most active GitHub users based on public contributionsprivate contributions and number of followers by country or state. The list updated 2025/8/29 3:05 PM UTC.
This repository contains users 19 countries and 130 cities.
To get into the list you need to have minimum number of followers that varies in each country. The list can be found in config.json.
Desenvolver uma aplicação utilizando javascript, css e html simulando a etapa de cadastro de endereço e escolha do mesmo para entregar de um produto.
PRÓXIMO PASSO
salvar os endereços em localstorage
uma segunda página ou aba dentro do mesmo formulário deve permitir ao usuário escolher entre os endereços previamente cadastrados como endereço para entrega, preenchendo assim os campos necessários
a página deve permitir a exclusão de um endereço já cadastrado
APERFEIÇOAMENTO
acessibilidade
REQUISITOS
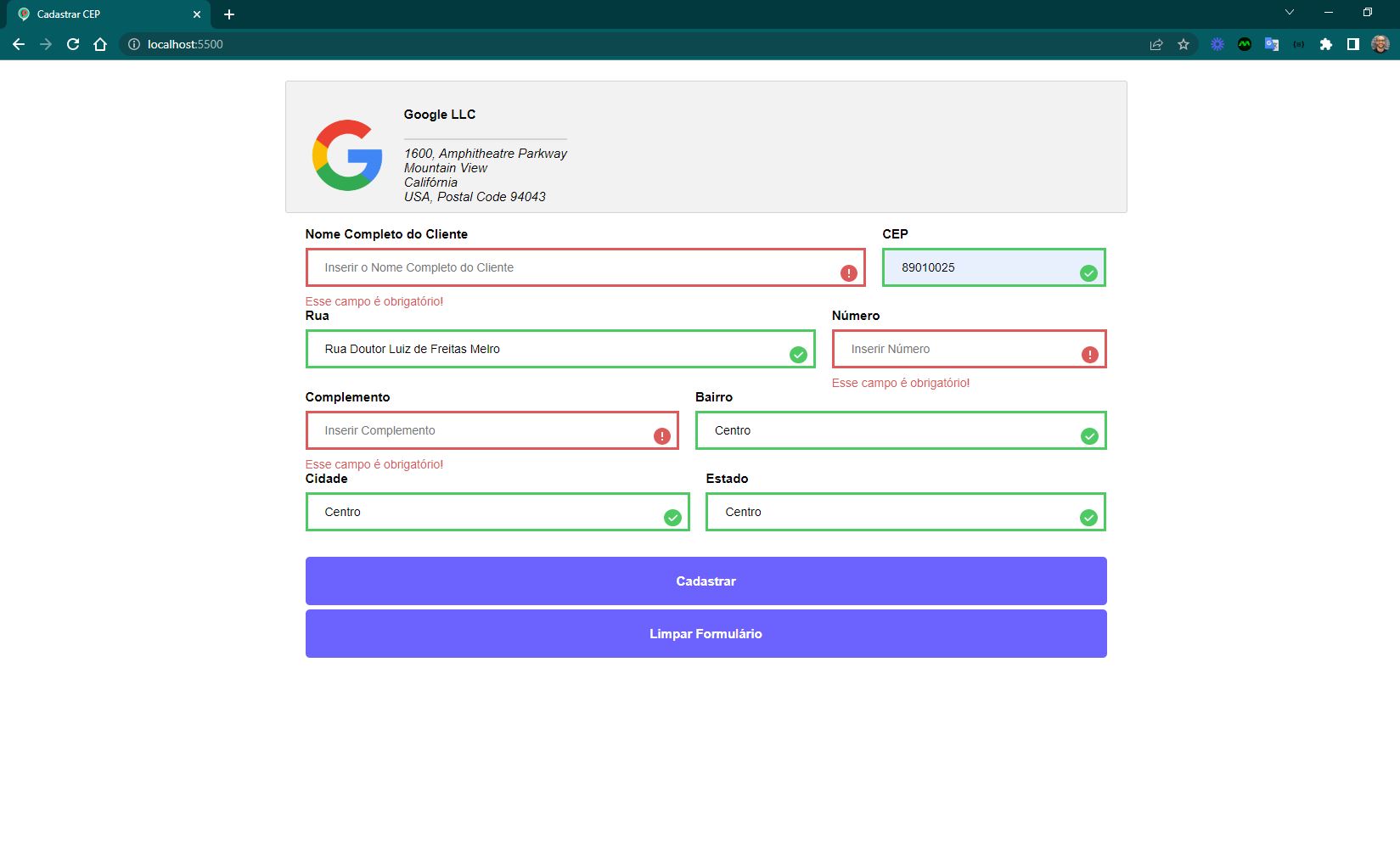
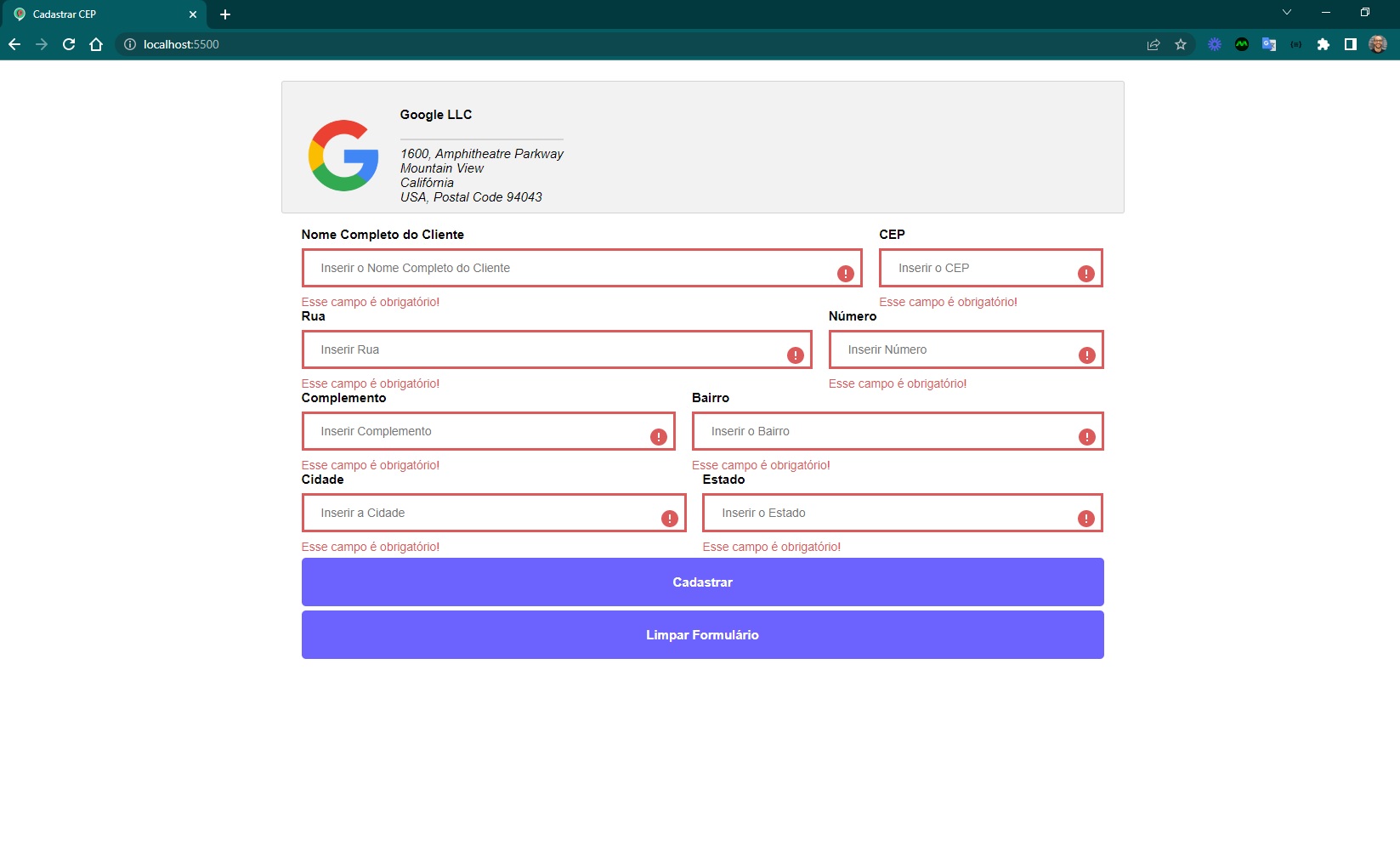
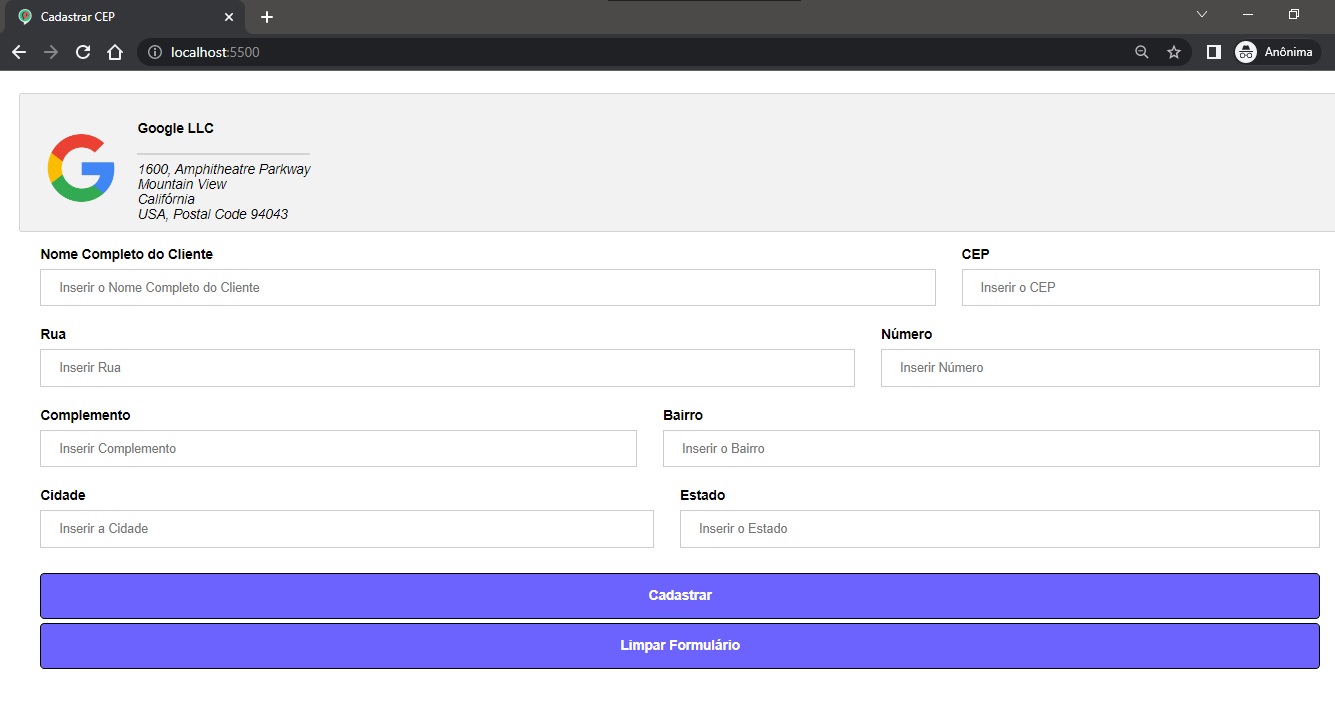
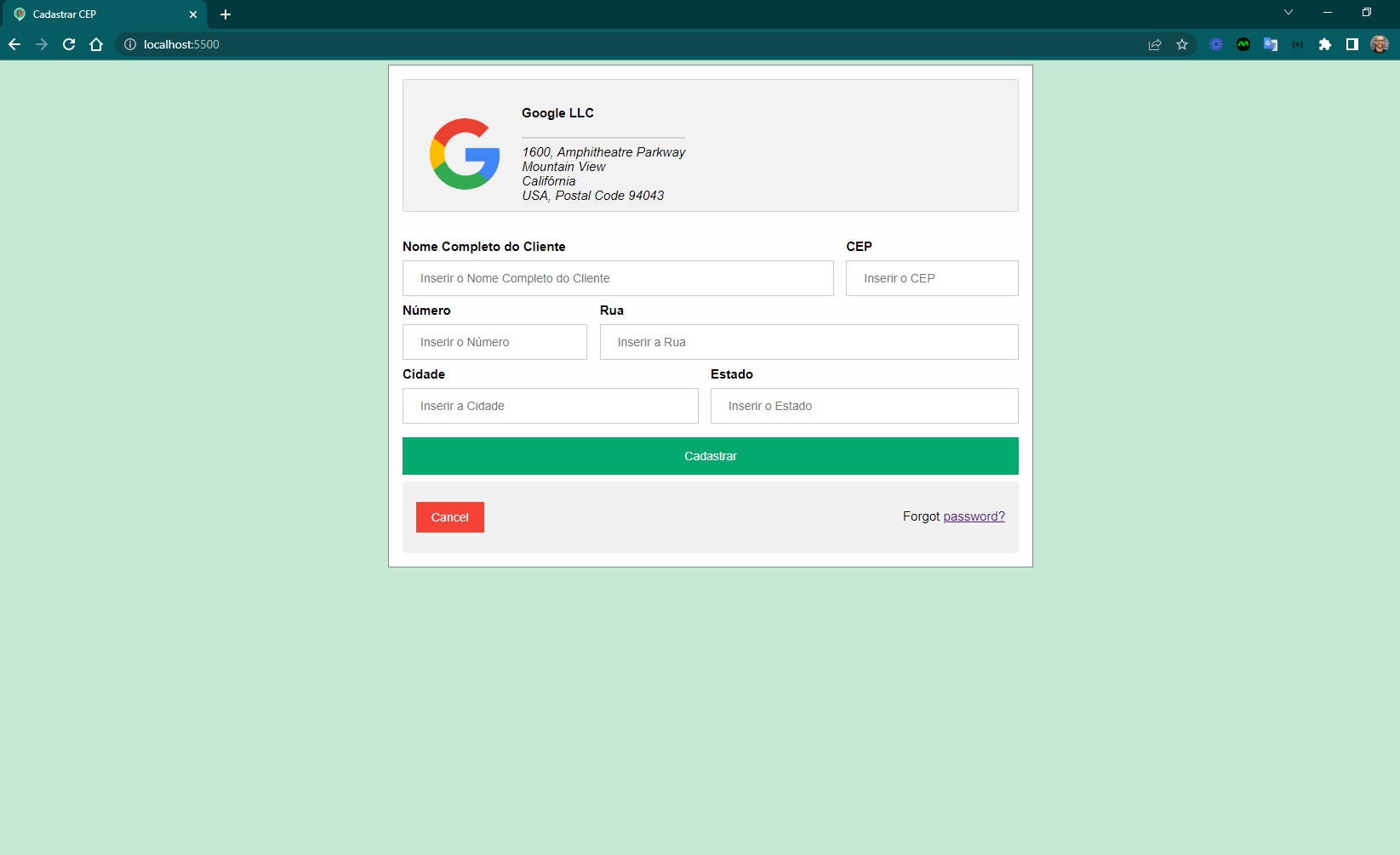
a página deve possuir um logo com endereço da empresa
a página deve possuir um formulário com os campos nome do cliente e endereço
os campos devem ser preenchidos automaticamente após informar o cep
o formulário deve conter as validações necessárias
EXTRAS
favicon
botão Enter vai para o próximo input com enterkeyhint="next"
We often want to collapse a collection into some summary of its elements.
This is known as a fold, a reduce, or a catamorphism:
List(1,2,3).foldLeft(0)(_ + _) // 6
How fast is this operation in the face of the JVM’s while and mutable
variables? For instance the familiar, manual, and error-prone:
varn:Int=0vari:Int= coll.length -1while (i >=0) {
n += coll(i)
i -=1
}
FoldBench compares List, scalaz.IList, Vector, Array, Stream, and Iterator for their speeds in various fold operations over Ints. FoldClassBench tries these same operations over a simple wrapping class to see
how boxing/references affect things.
Int Results:
All times are in microseconds. Entries marked with an asterisk are sped up by
optimization flags. Entries marked with two are slowed down by them.
Benchmark
List
IList
Vector
Array
Stream
EStream
Iterator
foldLeft
44.1**
31.3
63.5
34.0*
56.9
180.3**
55.4
foldRight
69.2
81.9
137.9*
36.3*
Stack Overflow
Stack Overflow
147.6
Tail Recursion
45.9
24.1
69.8
sum
76.9
71.0
79.0
74.7
while
44.0
38.4
3.0
52.9
45.4
Pair Class Results:
All times are in microseconds.
Benchmark
List
IList
Vector
Array
Stream
Iterator
foldLeft
39.5
37.5
70.2
39.9
68.2
65.8
foldRight
83.6
98.1
242.1
38.8
Stack Overflow
157.3
Tail Recursion
39.2
37.9
118.6**
while
39.3
57.8
36.2
70.1
39.2
Observations:
foldLeft is always better than both foldRight and manual tail recursion for
catamorphisms (reduction to a single value).
sum should be avoided.
Iterator benefits from while, but not enough to beat List.
Collections with random access (especially Array) benefit from while
loops.
Array has no advantage over List when holding non-primitive types!
Recommendation:
List.foldLeft is concise and performant for both primitive and boxed types.
If you were already dealing with an Array[Int] or likewise, then a while
loop will be faster.
Chained Higher-Order Functions
It’s common to string together multiple operations over a collection, say:
List(1,2,3,4).map(foo).filter(pred).map(bar)
which is certainly shorter and cleaner in its intent than manually manipulating
a mutable collection in a while loop. Are higher-order operations like these
still fast? People used to Haskell’s list fusion might point out that these
operations typically don’t fuse in Scala, meaning that each chained operation
fully iterates over the entire collection and allocates a new copy. Stream and Iterator are supposed to be the exceptions, however.
Stream in particular is what people wanting Haskell’s lazy lists may reach for
first, on the claim that the elements memoize, chained operations fuse, and they
support infinite streams of values. Let’s see how everything performs.
StreamBench performs the following operations on List, scalaz.IList, Vector, Array, Stream, scalaz.EphemeralStream and Iterator. We test:
Head: map-filter-map-head. Which collections “short-circuit”, only
fully processing the head and nothing else?
Max: map-filter-map-max. How quickly can each collection fully process itself?
Does fusion occur (esp. with Stream)?
Reverse: reverse-head. Can any of the collections “cheat” and grab the last
element quickly?
Sort: map-filter-map-sorted-head. Does Stream still leverage laziness with
a “mangling” operation like sort?
Results:
All times are in microseconds.
Benchmark
List
IList
Vector
Array
Stream
EStream
Iterator
Head
182.3
273.2
133.2
206.3
0.065
0.17
0.023
Max
198.9
401.7
263.5
192.7
863.7
1714.4
139.7
Reverse
37.8
49.2
146.7
45.6
371.6
448.5
Sort
327.5
607.6
277.8
289.4
1482.8
Observations:
Stream won’t do work it doesn’t have to, as advertised (re: Head).
Stream is very slow to fully evaluate, implying no operation fusion.
Nothing clever happens with sorting.
Iterator overall is the fastest collection to chain higher-order
functions.
List has the fastest reverse.
Recommendation:
If you want to chain higher-order operations in Scala, use an Iterator.
If you have something like a List instead, create an Iterator first
with .iterator before you chain.
Concatenation
Sometimes we need to merge two instances of a container together, end-to-end.
This is embodied by the classic operator ++, available for all the major
collection types.
We know that the collection types are implemented differently. Are some better
than others when it comes to ++? For instance, we might imagine that the
singly-linked List type would be quite bad at this. The lazy Stream types
should be instantaneous.
ConcatBench tests List, scalaz.IList, Array, Vector, Stream, and scalaz.EphemeralStream for their performance with the ++ operator. Two
results are offered for Array: one with Int and one for a simple Pair
class, to see if primitive Arrays can somehow be optimized here by the JVM, as
they usually are. Otherwise, the results are all for collections of Int.
All times are in microseconds.
Item Count
List
IList
Vector
Array[Int]
Array[Pair]
Stream
EStream
1,000
14
10
17
0.6
0.7
0.02
0.02
10,000
117
78
147
7
7
0.02
0.02
100,000
931
993
1209
75
77
0.02
0.02
1,000,000
8506
10101
10958
1777
1314
0.02
0.02
Observations:
The Stream types were instantaneous, as expected.
Array is quick! Somehow quicker for classes, though.
The drastic slowdown for Array at the millions-of-elements scale is strange.
IList beats List until millions-of-elements scale.
Vector has no advantage here, despite rumours to the contrary.
Recommendation:
If your algorithm requires concatenation of large collections, use Array.
If you’re worried about passing a mutable collection around your API, consider scalaz.ImmutableArray, a simple wrapper that prevents careless misuse.
Mutable Data
List, IList and Array
Above we saw that List performs strongly against Array when it comes to
chaining multiple higher-order functions together. What happens when we just
need to make a single transformation pass over our collection – in other words,
a .map? Array with a while loop is supposed to be the fastest iterating
operation on the JVM. Can List and IList still stand up to it?
MapBench compares these operations over increasing larger collection sizes of
both Int and a simple wrapper class.
Results:
All times are in microseconds.
Benchmark
List.map
IList.map
Array + while
100 Ints
0.77
1.1
0.05
1000 Ints
7.8
10.9
0.45
10000 Ints
71.6
99.9
3.7
100 Classes
0.83
1.3
0.4
1000 Classes
8.6
12.9
4.3
10000 Classes
81.3
111.2
43.1
Observations:
For List, there isn’t too much difference between Ints and classes.
Array is fast to do a single-pass iteration.
Recommendation:
If your code involves Array, primitives, and simple single-pass
transformations, then while loops will be fast for you. Otherwise, your code
will be cleaner and comparitively performant if you stick to immutable
collections and chained higher-order functions.
Builder Classes
You want to build up a new collection, perhaps iterating over an existing one,
perhaps from some live, dynamic process. For whatever reason .map and .foldLeft are not an option. Which collection is best for this? VectorBench
tests how fast each of List, scalaz.IList, ListBuffer, Vector, VectorBuilder, Array, ArrayBuilder, and IndexedSeq can create themselves
and accumulate values. For List, this is done with tail recursion. For IndexedSeq, this is done via a naive for-comprehension. For all others, this
is done with while loops. The Buffer and Builder classes perform a .result call at the end of iterating to take their non-builder forms (i.e. VectorBuilder => Vector). ArrayBuilder is given an overshot size hint (with .sizeHint) in order to realistically minimize inner Array copying.
Results:
All times are in microseconds.
Benchmark
List
IList
ListBuffer
Vector
VectorBuilder
Array
ArrayBuilder
IndexedSeq
1000 Ints
5.7
5.5
5.5
20.8
6.6
0.6
1.1
5.9
10000 Ints
60.2
57.1
57.9
206.1
39.0
5.3
11.4
61.4
100000 Ints
545.1
529.1
551.6
2091.2
384.3
53.3
121.3
615.3
1000 Classes
6.2
6.2
7.2
21.5
6.3
3.8
4.9
6.4
10000 Classes
64.4
62.4
68.5
214.3
44.7
41.4
53.1
65.4
100000 Classes
592.0
600.3
611.6
2164.7
429.4
357.0
523.5
653.3
Observations:
For primitives, Array is king.
Avoid appending to immutable Vectors.
Avoid repeated use of ListBuffer.prepend! Your runtime will slow by an order of magnitude vs +=:.
For classes, at small scales (~1000 elements) there is mostly no difference between
the various approaches.
ArrayBuilder can be useful if you’re able to ballpark what the final result size will be.
VectorBuilder fulfills the promise of Builders, but can only append to the right.
You’d have to deal with the fact that your elements are reversed.
Recommendation:
The best choice here depends on what your next step is.
If you plan to perform while -based numeric calculations over primitives only,
stick to Array. If using ArrayBuilder with primitives, avoid the .make
method. Use something like .ofInt instead. Also make sure that you use .sizeHint to avoid redundant inner Array copying as your collection grows.
Failing to do so can introduce a 5x slowdown.
Otherwise, consider whether your algorithm can’t be reexpressed entirely in
terms of Iterator. This will always give the best performance for subsequent
chained, higher-order functions.
If the algorithm can’t be expressed in terms of Iterator from the get-go, try
building your collection with VectorBuilder, call .iterator once filled,
then continue.
Mutable Set and Java’s ConcurrentHashMap
You’d like to build up a unique set of values and for some reason calling .toSet on your original collection isn’t enough. Perhaps you don’t have an
original collection. Scala’s collections have been criticized for their
performance, with one famous complaint saying how their team had to fallback to
using Java collection types entirely because the Scala ones couldn’t compare
(that was for Scala 2.8, mind you).
Is this true? UniquesBench compares both of Scala’s mutable and immutable Set types with Java’s ConcurrentHashMap to see which can accumulate unique
values faster.
Results:
All values are in microseconds.
Benchmark
mutable.Set
immutable.Set
Java ConcurrentHashMap
100 values
4.6
7.7
6.1
1000 values
62.2
107.4
71.3
10000 values
811.1*
1290.4
777.1
Note: About half the time the 10000-value benchmark for mutable.Set
optimizes down to ~600us instead of the ~800us shown in the chart.
Observations:
mutable.Set is fastest at least for small amounts of data, and might be
fastest at scale.
immutable.Set is slower and has worse growth, as expected.
Recommendation:
First consider whether your algorithm can’t be rewritten in terms of the usual
FP idioms, followed by a .toSet call to make the collection unique.
If that isn’t possible, then trust in the performance of native Scala
collections and use mutable.Set.
Pattern Matching
Deconstructing Containers
It’s common to decontruct containers like this in recursive algorithms:
defsafeHead[A](s: Seq[A]):Option[A] = s match {
caseSeq() =>Nonecase h +: _ =>Some(h)
}
But List and Stream have special “cons” operators, namely :: and #::
respectively. The List version of the above looks like:
defsafeHead[A](l: List[A]):Option[A] = l match {
caseNil=>Nonecase h :: _ =>Some(h)
}
How do these operators compare? Also, is it any slower to do it this way than a
more Java-like:
The MatchContainersBench benchmarks use a tail-recursive algorithm to find the
last element of each of List, scalaz.IList, Vector, Array, Seq, and Stream.
Results:
All times are in microseconds.
Benchmark
List
IList
Vector
Seq
Array
Stream
:: Matching
42.8
23.6
168.4
+: Matching
79.0
1647.5
707.4
170.2
if Statements
39.9
816.9
39.4
16020.6
55.8
Observations:
Canonical List and IList matching is fast.
Seq matching with +:, its canonical operator, is ironically slow.
Pattern matching with +: should be avoided in general.
if is generally faster than pattern matching, but the code isn’t as nice.
Avoid recursion with Vector and Array!
Array.tail is pure evil. Each call incurs ArrayOps wrapping and
seems to reallocate the entire Array. Vector.tail incurs a similar
slowdown, but not as drasticly.
Recommendation:
Recursion involving containers should be done with List and pattern matching
for the best balance of speed and simplicity. If you can take scalaz as a
dependency, its IList will be even faster.
Guard Patterns
It can sometimes be cleaner to check multiple Boolean conditions using a match:
deffoo(i: Int):Whatever= i match {
case _ if bar(i) =>???case _ if baz(i) =>???case _ if zoo(i) =>???case _ => someDefault
}
where we don’t really care about the pattern match, just the guard. This is in
constrast to if branches:
which of course would often be made more verbose by many {} pairs. Are we
punished for the empty pattern matches? MatchBench tests this, with various
numbers of branches.
Results:
All times are in nanoseconds.
Benchmark
Guards
Ifs
1 Condition
3.3
3.3
2 Conditions
3.6
3.6
3 Conditions
3.9
3.9
Identical! Feel free to use whichever you think is cleaner.
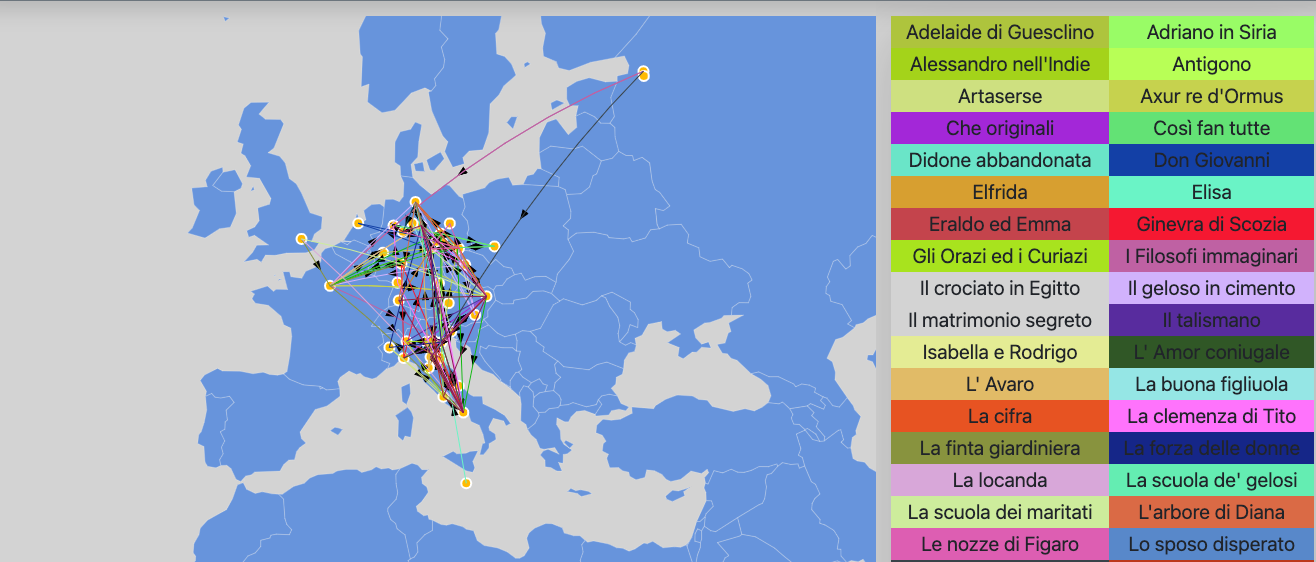
The project carried out aims to display information relating to a collection of opera performances that took place throughout Europe between 1775 and 1833.
Before Starting this adveture in first 800’s, we asked to ourself what we would learn from these data. After some documentation about opera world we were curios about:
How operas move throught nations and time?
Which are the most important cities where operas are perform?
How librettist and composer worked toghether?
How many operas they made?
With how many composers a librettist can work and vice versa?
…
These are just some of the questions that we tried to answer using graph visualization.
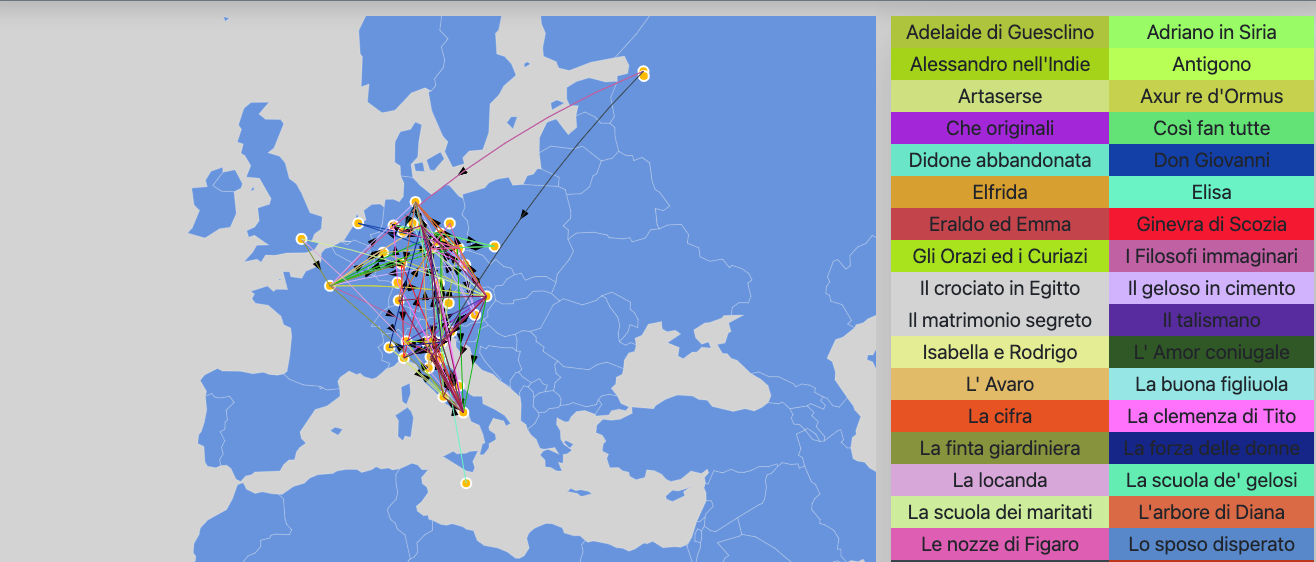
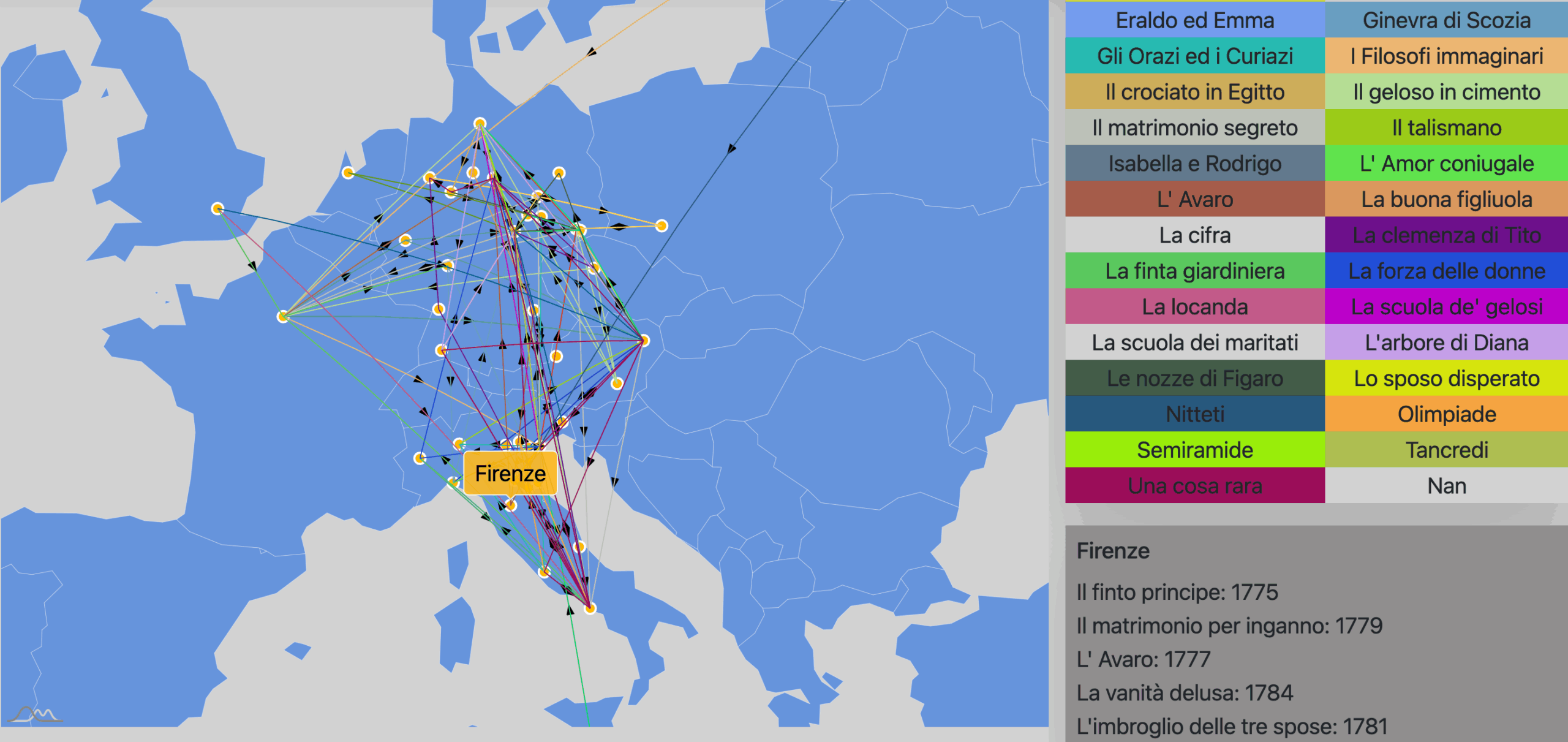
The map graphs aims to focus on the cities where the opera took place.
The nodes represent the cities while the edges between two nodes are present if and only if a opera was performed in both cities (the source and destination are established on the basis of the year in which the opera took place in the two cities).
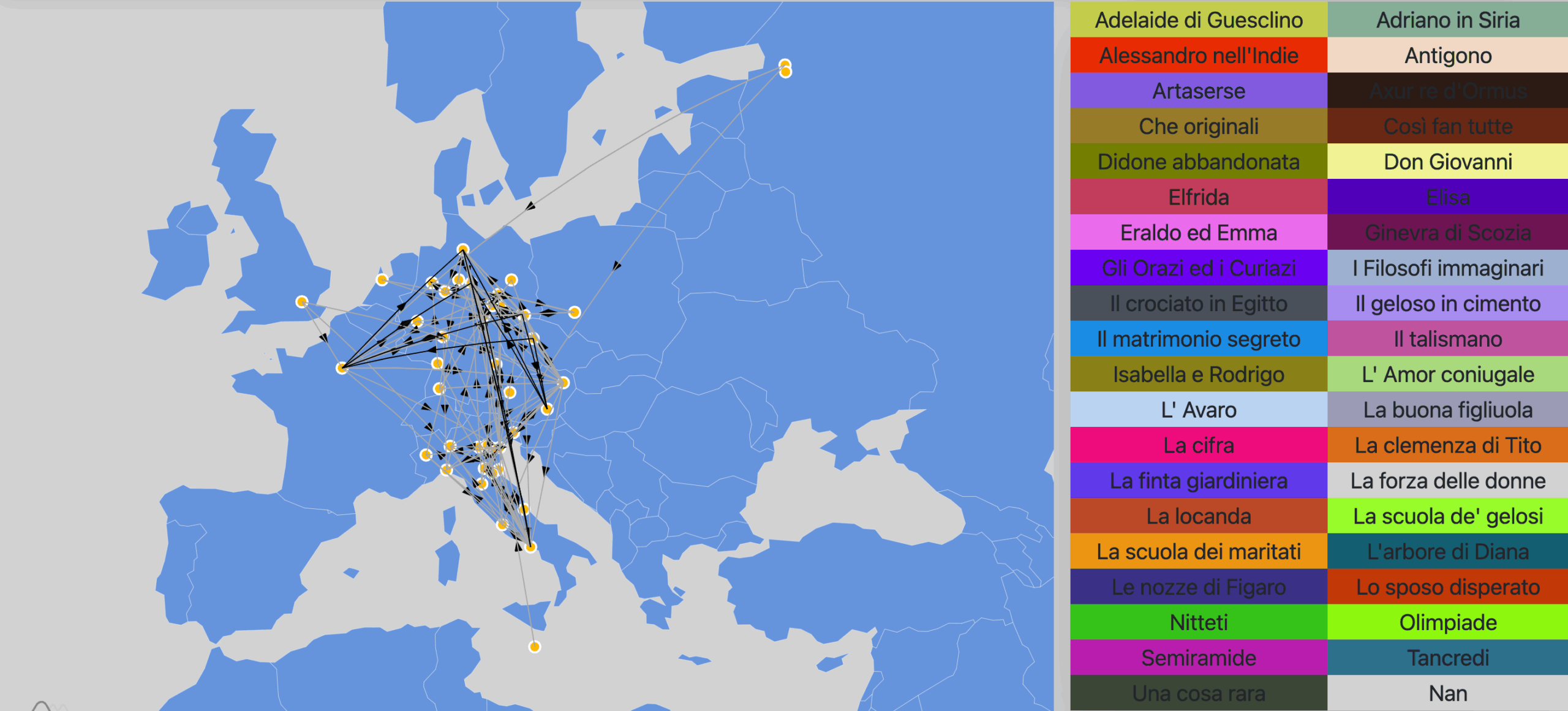
A second map graph shows only a few cities that hosted a opera that took place nowhere else.
The edges represent this common feature between the various cities in question.
Interactions
When the mouse passes over the nodes, the name of the city appears. If you select a node, information on the names and years of the opera that took place in that city appears.
By clicking on the legend you have a focus on the individual opera, highlighting only the edges involved.
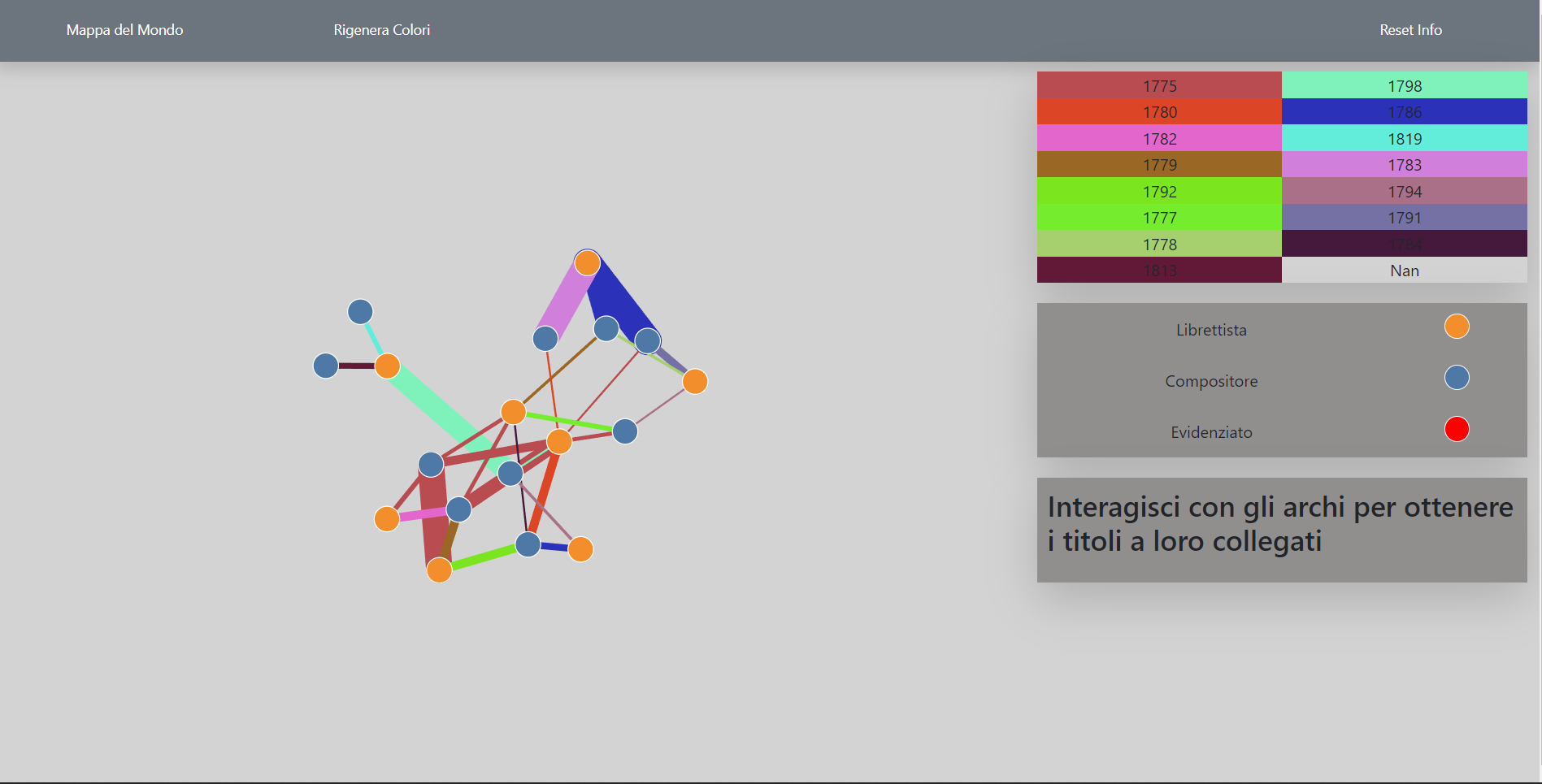
Force Directed Graph
The force directed graph aim to focus on reletionship between librettist and composer.
Blu nodes reppresent composer, while orange nodes are librettist. These nodes are connected by edges if and only if they worked toghether at least one time, while edges color and thickness, represent respectively the first year that a librettist and a composer worked toghether and the number of time that they worked toghether.
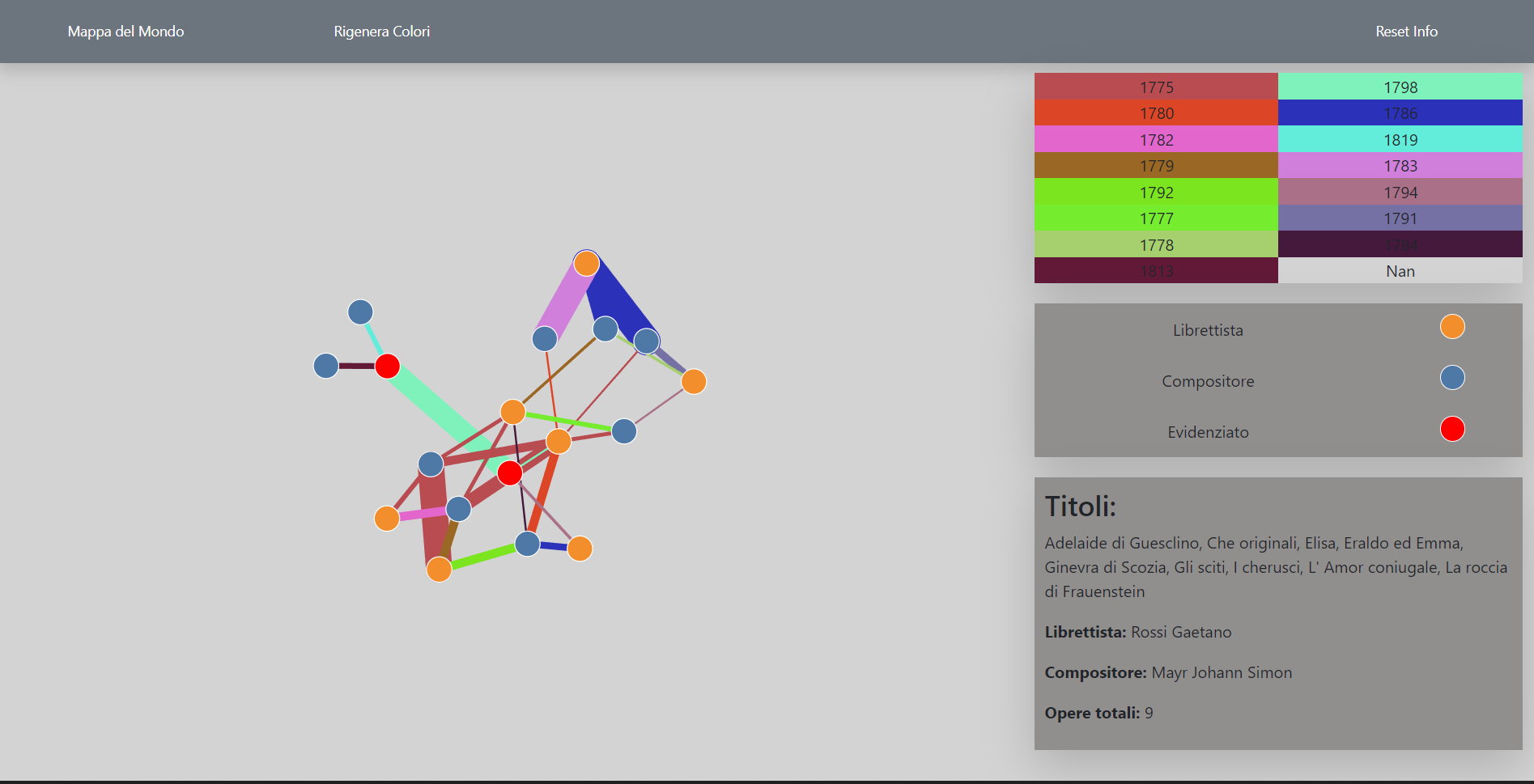
Interactions
When a click event happen on a edge the two nodes connected to that edge change color to red, while dark grey rectangle under nodes legend, it shows operas titles and number of operas which librettist and composer made toghether.
Header
The header is a composition of 3 button:
Mappa del Mondo: Load Map graph
Rigenera Colori: Reload the page and assign new edges colors
Reset info: Restore Information and red nodes to their original appearance.
The project carried out aims to display information relating to a collection of opera performances that took place throughout Europe between 1775 and 1833.
Before Starting this adveture in first 800’s, we asked to ourself what we would learn from these data. After some documentation about opera world we were curios about:
How operas move throught nations and time?
Which are the most important cities where operas are perform?
How librettist and composer worked toghether?
How many operas they made?
With how many composers a librettist can work and vice versa?
…
These are just some of the questions that we tried to answer using graph visualization.
The map graphs aims to focus on the cities where the opera took place.
The nodes represent the cities while the edges between two nodes are present if and only if a opera was performed in both cities (the source and destination are established on the basis of the year in which the opera took place in the two cities).
A second map graph shows only a few cities that hosted a opera that took place nowhere else.
The edges represent this common feature between the various cities in question.
Interactions
When the mouse passes over the nodes, the name of the city appears. If you select a node, information on the names and years of the opera that took place in that city appears.
By clicking on the legend you have a focus on the individual opera, highlighting only the edges involved.
Force Directed Graph
The force directed graph aim to focus on reletionship between librettist and composer.
Blu nodes reppresent composer, while orange nodes are librettist. These nodes are connected by edges if and only if they worked toghether at least one time, while edges color and thickness, represent respectively the first year that a librettist and a composer worked toghether and the number of time that they worked toghether.
Interactions
When a click event happen on a edge the two nodes connected to that edge change color to red, while dark grey rectangle under nodes legend, it shows operas titles and number of operas which librettist and composer made toghether.
Header
The header is a composition of 3 button:
Mappa del Mondo: Load Map graph
Rigenera Colori: Reload the page and assign new edges colors
Reset info: Restore Information and red nodes to their original appearance.
Installs php-fpm from IUS Community Project RPMs on RHEL / CentOS 7. Where archived verions of php are required, the ius-archive repository may be enabled.
Currently this role installs php-fpm pre-configured with defaults built around the Magento 2 application. Some of these defaults may be high than required for other applications of the php-fpm service. One of these areas would by the php-opcache defaults, which must be very high for high Magento 2 application performance and may otherwise be reduced. See defaults/main.yml and vars/opcache.yml for details.
Requirements
None.
Role Variables
php_version: 73
Any php version supported by IUS RPMs may be specified: 55, 56, 70, 71, 72, 73, 74, etc. For older versions, php_enablerepo: ius-archive will also need to be specified.
See defaults/main.yml for complete list of variables available to customize the php-fpm installation.