
This repository has been developed primarily by @ajaen4, @adrij and @alfonjerezi.
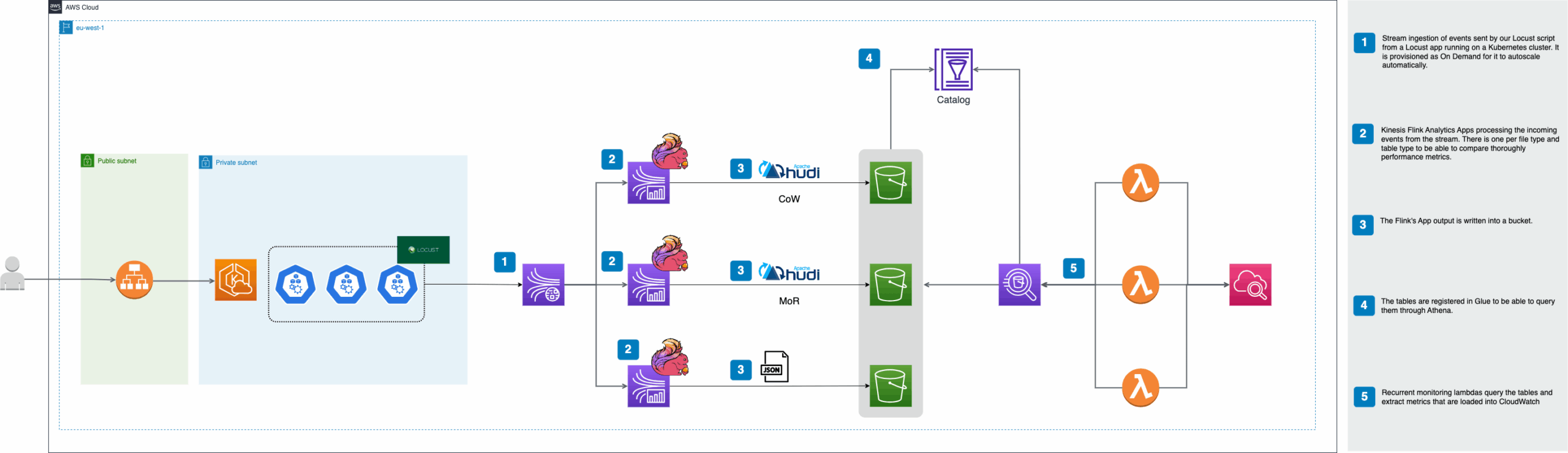
This project deploys an architecture in AWS which ingest and processes streaming data with Kinesis Flink Application and writes the output to S3 in Hudi and JSON format.

Articles:
-
You must own an AWS account and have an Access Key to be able to authenticate. You need this so every script or deployment is done with the correct credentials. See here steps to configure your credentials.
-
Versions:
- Terraform = 1.1.7
- terraform-docs = 0.16.0
- hashicorp/aws = 4.54.0
- Python = 3.8
This code will deploy the following infraestructure inside AWS:
- 3 Kinesis Flink Applications
- 1 Kinesis Data Streams
- 3 S3 bucket
- Deployment bucket
- JSON data bucket
- Hudi COW data bucket
- Hudi MOR data bucket
- 1 EKS Cluster
- 1 Locust app deployed in the EKS Cluster
- 3 Monitoring Lambdas (1 per output type)
Follow the instructions here to install terraform
Follow the instructions here to install the AWS CLI
Follow the instructions here to install Python 3.8
In order to run any python code locally you will need to create a virtual env first and install all requirements:
python3 -m venv .venv
source .venv/bin/activateIn the case of using Microsoft:
python3 -m venv .venv
.\env\Scripts\activateAnd to install all required packages:
make installThis small infra deployment is to be able to use remote state with Terraform. See more info about remote state here. Commands:
cd infra/bootstraper-terraform
terraform init
terraform <plan/apply/destroy> -var-file=vars/bootstraper.tfvars
# Example
cd infra/bootstraper-terraform
terraform init
terraform apply -var-file=vars/bootstraper.tfvarsIt is important that you choose wisely the variables declared in the “bootstraper-terrafom/vars/bootstraper.tfvars” file because the bucket name is formed using these.
There will be an output printed on the terminal’s screen, this could be an example:
state_bucket_name = "eu-west-1-bluetab-cm-vpc-tfstate"Please copy it, we will be using it in the next chapter.
Important: we have set some big and expensive instances in the vars/flink-hudi.tfvars variables file. We recommend you set this variables appropiately to not incurr in excessive costs.
To be able to deploy the infrastructure it’s necessary to fill in the variables file (“vars/flink-hudi.tfvars”) and the backend config for the remote state (“terraform.tf”).
To deploy, the following commands must be run:
terraform <plan/apply/destroy> -var-file=vars/flink-hudi.tfvarsWe will use the value copied in the previous chapter, the state bucket name, to substitute the <OUTPUT_FROM_BOOTSTRAPER_TERRAFORM> value in the infra/backend.tf file. You will need docker and the docker daemon running in order to perform the deployment.
Once deployed, you can make use of the provided Locust application to send events to the Kinesis Stream. Just make sure that the environment variables are properly configured in event_generation/.env (add AWS_PROFILE if you want to use a different one from the default) and run:
make send-recordsA Locust process will start and you can access its UI in http://0.0.0.0:8089/. You can modify number of users and rate, but the defaults will suffice for testing the application.
After deploying all the infrastructure you will see an output called load_balancer_dns. Its value is an URL, copy and paste it in your web browser to see the Locust interface. Choose the configuration for your loadtest and click “Start swarming”. You will start to receive events inmediatly to the designated kinesis stream!.
Some dependencies are needed for the Flink application to work properly which entail some explanation
flink-sql-connector-kinesis– Fundamental connector for our Flink application to be able to read from a Kinesis Stream.flink-s3-fs-hadoop– Allows the application to operate on top of S3.hudi-flink1.15-bundle– Package provided by Hudi developers, with all the necessary dependencies to work with the technology.hadoop-mapreduce-client-core– Additional dependency required for writing to Hudi to work correctly in KDA. It is possible that in future versions of the Hudi Bundle this dependency will not be needed.aws-java-sdk-glue,hive-common,hive-exec– Necessary dependencies for the integration between Hudi and AWS Glue Catalog
MIT License – Copyright (c) 2023 The kinesis-flink-hudi-benchmark Authors.
 https://github.com/ajaen4/kinesis-flink-hudi-benchmark
https://github.com/ajaen4/kinesis-flink-hudi-benchmark
Leave a Reply