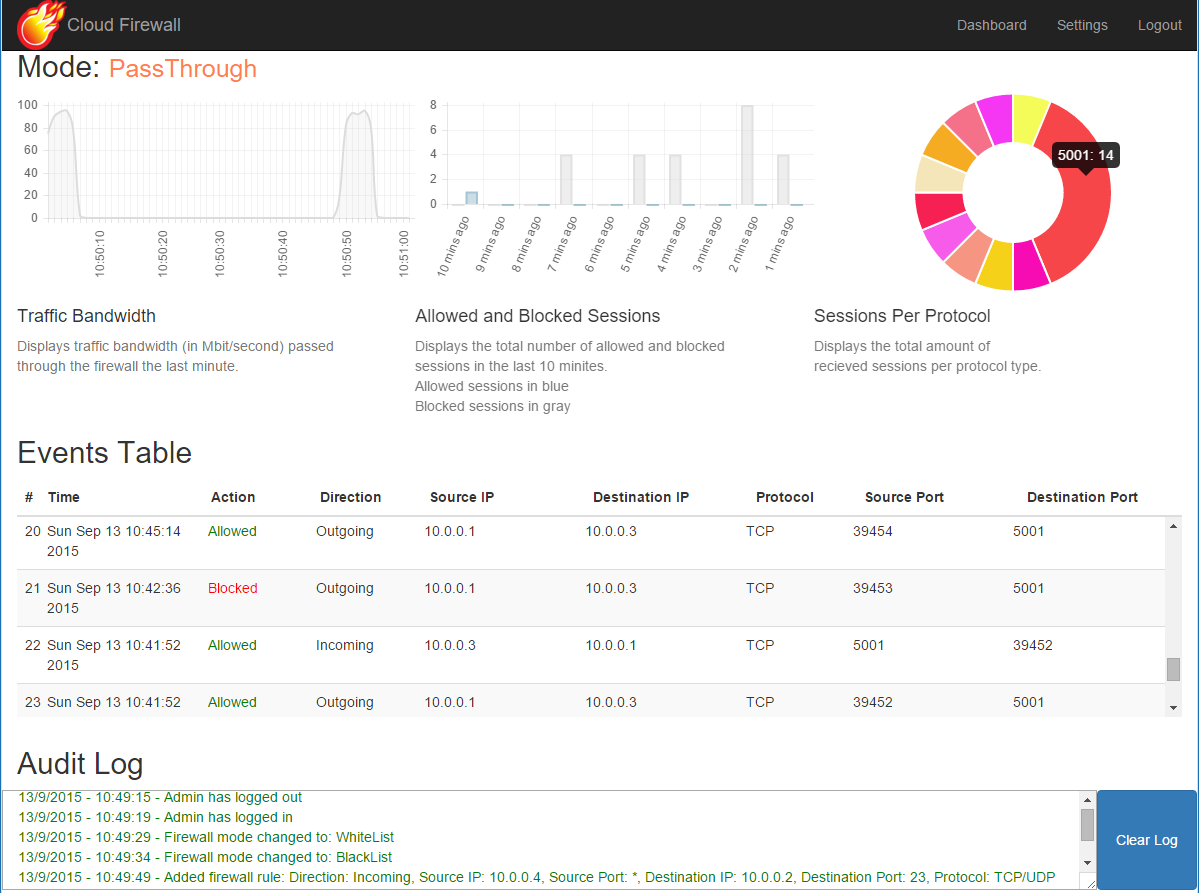
--{{0}}--
This document defines some basic macros for applying the
mec2 2D physics simulation in
LiaScript.
Try it on LiaScript:
See the project on Github:
https://github.com/liaTemplates/mec2
--{{1}}--
There are three ways to use this template. The easiest way is to use the
import statement and the url of the raw text-file of the master branch or any
other branch or version. But you can also copy the required functionionality
directly into the header of your Markdown document, see therefor the
last slide. And of course, you could also clone this project
and change it, as you wish.
{{1}}
-
Load the macros via
import: https://raw.githubusercontent.com/LiaTemplates/mec2/main/README.md -
Copy the definitions into your Project
-
Clone this repository on GitHub
--{{0}}--
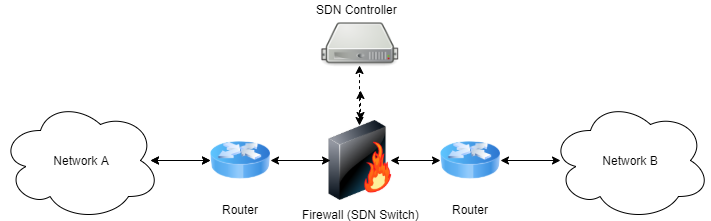
Simply add @mec2 directly to the head of your Markdown code-snippet to execute
it directly within LiaScript.
{
"id":"chaos-pendulums",
"gravity":true,
"nodes": [
{ "id":"A0","x":200,"y":400,"base":true },
{ "id":"A1","x":280,"y":480,"m":2 },
{ "id":"B1","x":279,"y":481,"m":2 },
{ "id":"C1","x":278,"y":482,"m":2 },
{ "id":"D1","x":277,"y":483,"m":2 },
{ "id":"A2","x":360,"y":560,"m":3 },
{ "id":"B2","x":359,"y":561,"m":3 },
{ "id":"C2","x":358,"y":562,"m":3 },
{ "id":"D2","x":357,"y":563,"m":3 },
{ "id":"A3","x":440,"y":640,"m":4.7 },
{ "id":"B3","x":439,"y":641,"m":4.7 },
{ "id":"C3","x":438,"y":642,"m":4.7 },
{ "id":"D3","x":437,"y":643,"m":4.7 }
],
"constraints": [
{ "id":"a1","p1":"A0","p2":"A1","len":{ "type":"const" } },
{ "id":"a2","p1":"A1","p2":"A2","len":{ "type":"const" } },
{ "id":"a3","p1":"A2","p2":"A3","len":{ "type":"const" } },
{ "id":"b1","p1":"A0","p2":"B1","len":{ "type":"const" } },
{ "id":"b2","p1":"B1","p2":"B2","len":{ "type":"const" } },
{ "id":"b3","p1":"B2","p2":"B3","len":{ "type":"const" } },
{ "id":"c1","p1":"A0","p2":"C1","len":{ "type":"const" } },
{ "id":"c2","p1":"C1","p2":"C2","len":{ "type":"const" } },
{ "id":"c3","p1":"C2","p2":"C3","len":{ "type":"const" } },
{ "id":"d1","p1":"A0","p2":"D1","len":{ "type":"const" } },
{ "id":"d2","p1":"D1","p2":"D2","len":{ "type":"const" } },
{ "id":"d3","p1":"D2","p2":"D3","len":{ "type":"const" } }
],
"views": [
{ "show":"pos","of":"A3","as":"trace","id":"view1","stroke":"rgba(255,0,0,.5)" },
{ "show":"pos","of":"B3","as":"trace","id":"view2","stroke":"rgba(0,255,0,.5)" },
{ "show":"pos","of":"C3","as":"trace","id":"view3","stroke":"rgba(255,255,0,.5)" },
{ "show":"pos","of":"D3","as":"trace","id":"view4","stroke":"rgba(255,0,255,.5)" }
]
}
--{{0}}--
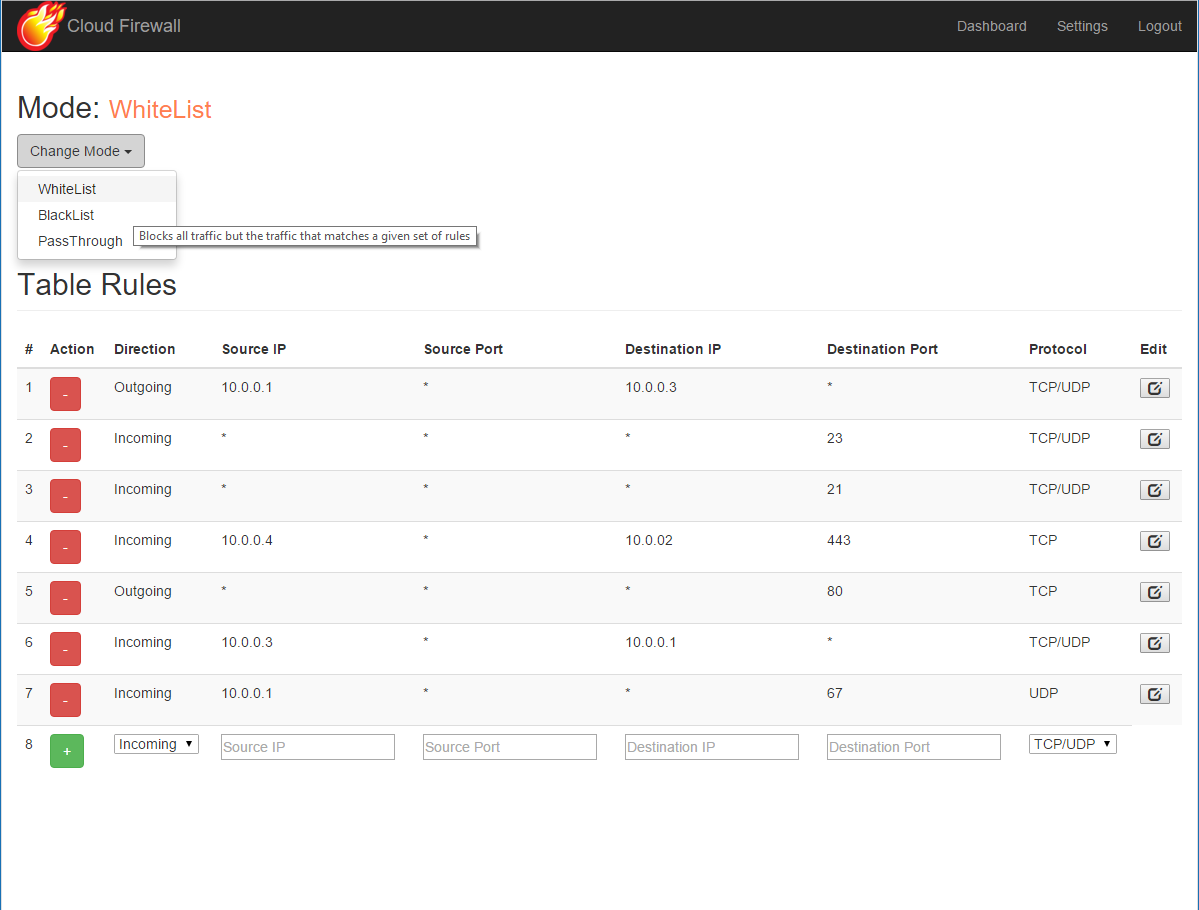
Attach @mec2.eval to the end of your Markdown code-snippet to create an
editable and executeable simulation.
{
"id":"chaos-pendulums",
"gravity":true,
"nodes": [
{ "id":"A0","x":200,"y":400,"base":true },
{ "id":"A1","x":280,"y":480,"m":2 },
{ "id":"B1","x":279,"y":481,"m":2 },
{ "id":"C1","x":278,"y":482,"m":2 },
{ "id":"D1","x":277,"y":483,"m":2 },
{ "id":"A2","x":360,"y":560,"m":3 },
{ "id":"B2","x":359,"y":561,"m":3 },
{ "id":"C2","x":358,"y":562,"m":3 },
{ "id":"D2","x":357,"y":563,"m":3 },
{ "id":"A3","x":440,"y":640,"m":4.7 },
{ "id":"B3","x":439,"y":641,"m":4.7 },
{ "id":"C3","x":438,"y":642,"m":4.7 },
{ "id":"D3","x":437,"y":643,"m":4.7 }
],
"constraints": [
{ "id":"a1","p1":"A0","p2":"A1","len":{ "type":"const" } },
{ "id":"a2","p1":"A1","p2":"A2","len":{ "type":"const" } },
{ "id":"a3","p1":"A2","p2":"A3","len":{ "type":"const" } },
{ "id":"b1","p1":"A0","p2":"B1","len":{ "type":"const" } },
{ "id":"b2","p1":"B1","p2":"B2","len":{ "type":"const" } },
{ "id":"b3","p1":"B2","p2":"B3","len":{ "type":"const" } },
{ "id":"c1","p1":"A0","p2":"C1","len":{ "type":"const" } },
{ "id":"c2","p1":"C1","p2":"C2","len":{ "type":"const" } },
{ "id":"c3","p1":"C2","p2":"C3","len":{ "type":"const" } },
{ "id":"d1","p1":"A0","p2":"D1","len":{ "type":"const" } },
{ "id":"d2","p1":"D1","p2":"D2","len":{ "type":"const" } },
{ "id":"d3","p1":"D2","p2":"D3","len":{ "type":"const" } }
],
"views": [
{ "show":"pos","of":"A3","as":"trace","id":"view1","stroke":"rgba(255,0,0,.5)" },
{ "show":"pos","of":"B3","as":"trace","id":"view2","stroke":"rgba(0,255,0,.5)" },
{ "show":"pos","of":"C3","as":"trace","id":"view3","stroke":"rgba(255,255,0,.5)" },
{ "show":"pos","of":"D3","as":"trace","id":"view4","stroke":"rgba(255,0,255,.5)" }
]
}
@mec2.eval
script: https://jauhl.github.io/mecEdit/scripts/g2.js
https://jauhl.github.io/mecEdit/scripts/mec2.min.js
https://jauhl.github.io/mecEdit/scripts/mecelement/canvasInteractor.js
https://jauhl.github.io/mecEdit/scripts/mecelement/g2.selector.js
https://jauhl.github.io/mecEdit/scripts/mecelement/mec.htmlelement.js
@mec2
<lia-keep>
<MEC-2 width=800 height=600 grid cartesian darkmode x0=385 y0=139 >
@0
</MEC-2>
</lia-keep>
@end
@mec2.eval: @mec2.eval_(@uid)
@mec2.eval_
<script>
let json=`@input`
document.getElementById("@0").innerHTML = "<MEC-2 id='test' width=1530 height=680 grid cartesian darkmode x0=385 y0=139 >" + json + "</MEC-2>"
"LIA: stop"
</script>
<div id="@0"></div>
@end