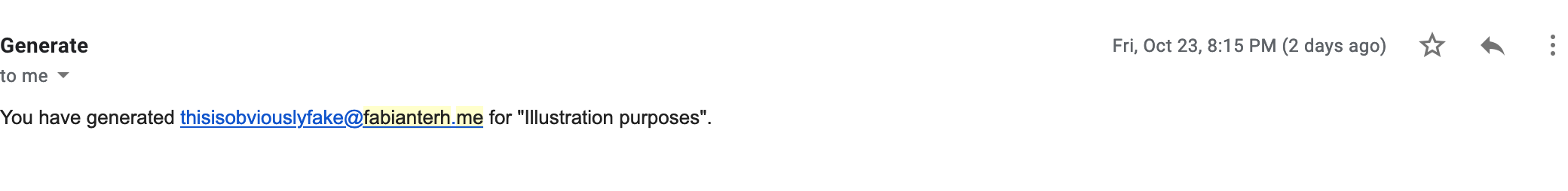Heimdall is a self-hosted email alias/forwarding service.
I built this as a privacy tool to fight spam and also better manage access to my personal email address.
As a self-hosted and self-managed service, you have complete control over your data.
With 3rd party email forwarding services, you are forced to trust a company with your emails.
This has also been a really fun project for me to learn more about AWS and the Serverless framework.
Check out: How I built Heimdall, an open-source personal email guardian.
Changelog can be found under Releases.
- With Heimdall, you completely own and manage your data and the service. No feature limitations or having to trust a third-party company with your data.
- Heimdall is meant for individual users to deploy and use and contains user-friendly setup instructions.
- Heimdall is easy to run – it utilizes the idea of serverless computing, so there is zero server configuration or provisioning.
- Heimdall is easy to deploy – it uses the Serverless framework (not to be confused with small-letter serverless in Point 3 above) so you can deploy with a single command.
- Receive safely: Receive emails on single-use aliases and forward them to your personal inbox.
- Reply anonymously: Reply to emails from your alias without revealing your personal email address.
- Attachments: Attachments are supported on incoming and outgoing emails (subject to size limits – see below).
- Email commands: Manage your aliases through email directly – no separate app or website required.
- Usage stats: Easily check the usage stats of each alias.
Heimdall operates as a whitelisting (default-deny) service.
All incoming emails to your domain are rejected by default unless they are to valid aliases.
Emails received on valid aliases will be forwarded to your personal email address.
Forwarded emails will preserve metadata information, such as any other recipients in the “to” or “CC” headers.
To reply, simply reply normally to the received email.
Other recipients in the original email will not receive your reply.
You may include other recipients in the “to” and “CC” list,
either by manually inserting them, or using “reply-all”.
Note: If you do that, you will disclose your email address to them.
However, the original sender will still not be able to see your email address, provided you are replying to the original sender through the alias.
The original sender will also not be able to see the other recipients.
Attachments are supported, although size limits apply to the entire email message.
This is a hard limitation imposed by AWS and cannot be circumvented.
See Limitations below.
To interact with the service, send a single email to one of the following email addresses.
Email generate@yourverifieddomain.com with the description as the subject. You will receive the generated alias as a reply.
The description lets you identify an alias and its use. E.g. “Sign up for Service X”.
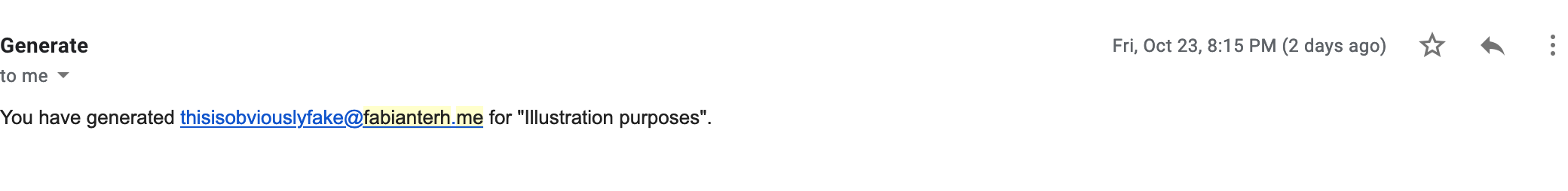
Email list@yourverifieddomain.com. You will receive a list of all aliases as a reply.
Dev note: This reads up to a maximum of 1MB of data (due to AWS’s limitations).
Email remove@yourverifieddomain.com with the alias as the title (case-sensitive). You will receive the operation outcome (success/failure) as a reply.
Email info@yourverifieddomain.com with the alias as the title (case-sensitive).
You will receive usage information for the particular alias.
Supported usage stats:
- Alias creation date
- Emails received
- Emails sent
- Date of last received email
- Date of last sent email
Coming soon – not supported yet.
Received emails must be <30MB. Outgoing emails must be <10MB.
Pre-requisites: You need to own a domain and have an AWS account.
For reasonable use cases, you should not exceed AWS’s free tier (which is very generous).
You should also already have Yarn and NodeJS installed.
Optional: To be able to reply to emails, you need to request AWS Support to un-sandbox your SES account.
- Add and verify your domain in AWS Simple Email Service (SES).
- In AWS’s SES console, generate a set of SMTP credentials.
Take note of that, and also your connection information on SES’s “SMTP Settings” page.
- Populate required environment variables in
.env.sample, and rename to .env.
It is important that EMAIL matches your personal email exactly.
Also note that you should avoid port 25, due to AWS’s default blocking of outbound traffic.
- Run
yarn global add serverless. Then, check out Serverless’s guide to set up Serverless’s credentials for accessing your AWS account programmatically.
- Run
yarn install.
- Set up Serverless, then run
yarn run deploy-prod.
- Add a receipt rule in SES to trigger your S3 bucket (created in step 6).
For “recipients”, enter your domain name (e.g.
yourverifieddomain.com).
Preferably, name your rule descriptively (e.g. prod).
If you want to build new features or tweak existing features, you can set up a parallel development environment that runs alongside production (above).
- Ensure that the
DEV_SUBDOMAIN environment variable is set in .env (e.g. test).
- Run
yarn run deploy-dev.
This creates a parallel development CloudFormation stack.
- Add a new receipt rule in SES before your production rule to trigger your development S3 bucket.
For “recipients”, enter the same test subdomain as you set in step 1 (e.g.
test.yourverifieddomain.com).
Preferably, name your rule descriptively (e.g. dev).
Note: You need to update your DNS records for test.yourverifieddomain.com as you did when verifying your domain for AWS SES.
To run migration scripts, first compile using tsc scripts/migrate_vX.ts, then run using node scripts/migrate_vX.js.













 https://github.com/NidhoggDJoking/vitepress
https://github.com/NidhoggDJoking/vitepress